异常检测
问题
已知训练数据 找到一个函数,判断输入x是否与训练数据相似
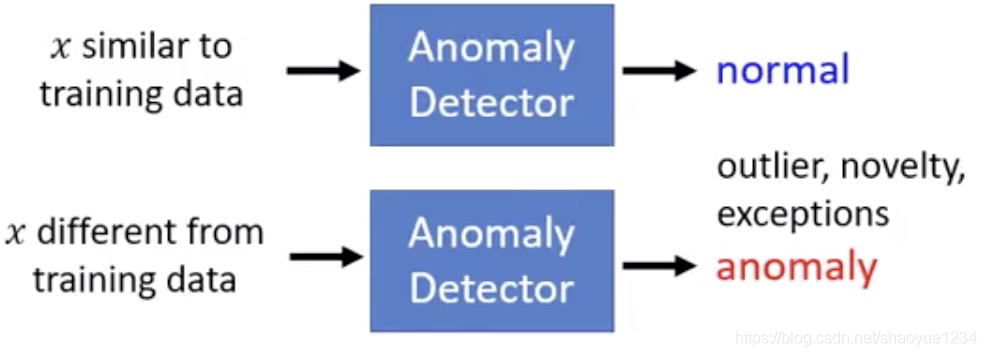
(anomaly不一定是不好的,也被称为novelty,outlier,exceptions detection)
什么是anomaly
取决于训练数据,与训练数据不同的就是异常的。

应用
fraud detection
训练数据:正常刷卡行为 异常数据:盗刷
network instrusion detection
训练数据:正常连线 异常数据:攻击行为
cancer detection
训练数据:正常细胞 异常数据:癌细胞
如何做异常检测
binary classification?
类1:正常数据 类2:异常数据 不能解决
原因1:异常数据太多,无法穷举  原因2:异常数据不好收集
原因2:异常数据不好收集
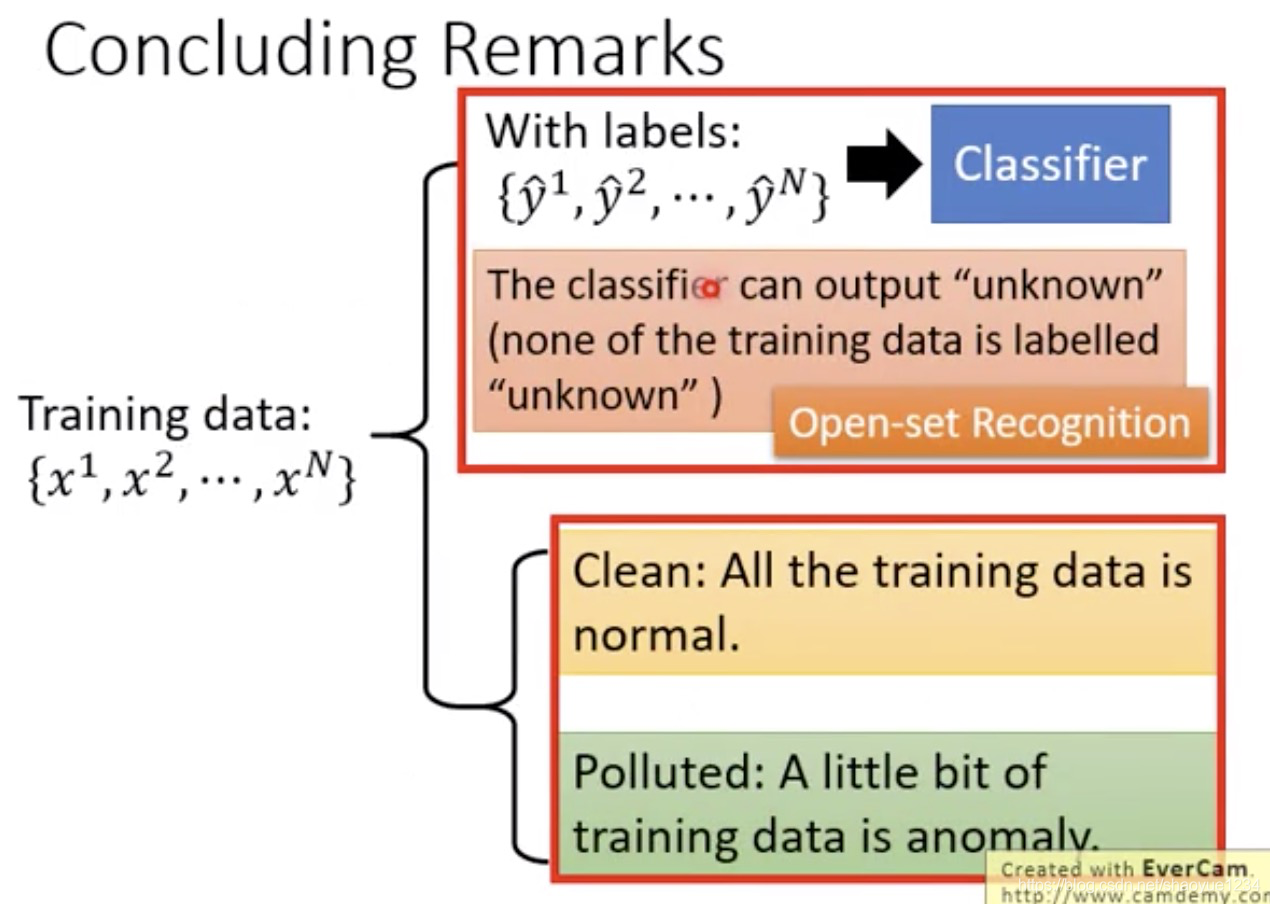
分类
- 训练数据有标签,没见过的东西输出unknown(open-set recognition)模型是open的,能够对没见过的东西进行判断。
- 训练数据没有标签
干净的数据 数据有脏东西(anomaly)
with label
例子——辛普森一家分类器
方法
使用现成分类器
训练一个分类器,给出每个类比的confidence
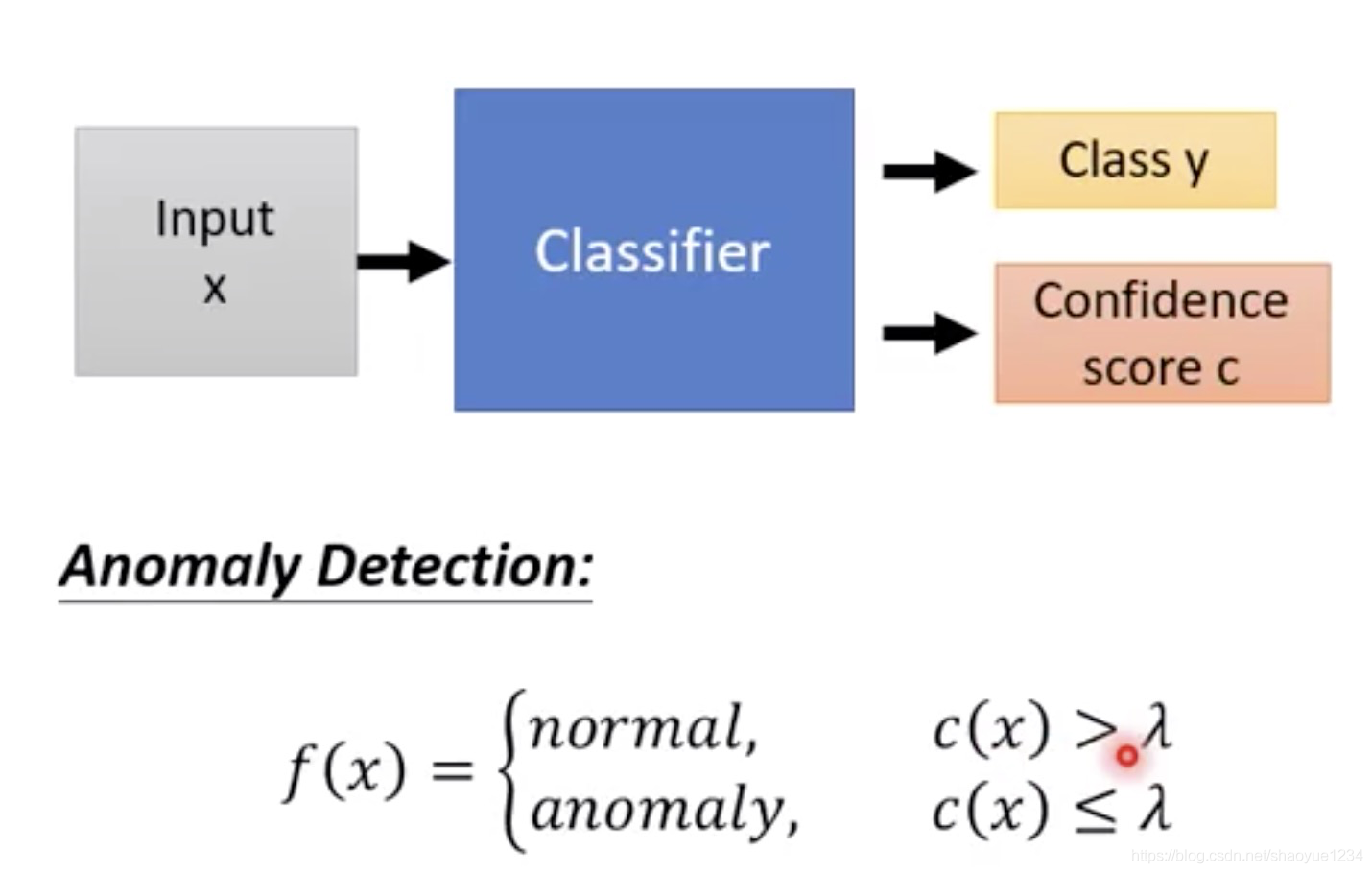
设置一个阈值大于该阈值是辛普森,小于该阈值是异常。
可行的方法 confidence:给出最大的confidence entropy:给出熵(乱度),entropy越大说明分布平均,不确定是哪个类别。
训练一个可以直接输出confidence的网络
框架
训练集:辛普森一家的图片,每个图片x有标签y。训练分类器。获得confidence,根据是否超过阈值判断是否为anomaly 验证集(模仿测试集):图片中有辛普森一家的人,也有不是的。 可以通过验证集来计算f(x)的表现,确定超参数的值(比如阈值) 测试集:输入图片x,判断是不是辛普森一家。

评估
方式:在dev set上对模型评价 注意:使用正确率不是一个好的指标。因为正负样本的比例悬殊。 一个系统可能正确率很高,但是并没有意义。 False alarm:正常被侦测为异常。 mising:异常被侦测为正常。 一个系统的好与坏,取决于False alarm比较重要,还是mising比较重要。 可以利用cost table来衡量系统的好坏。
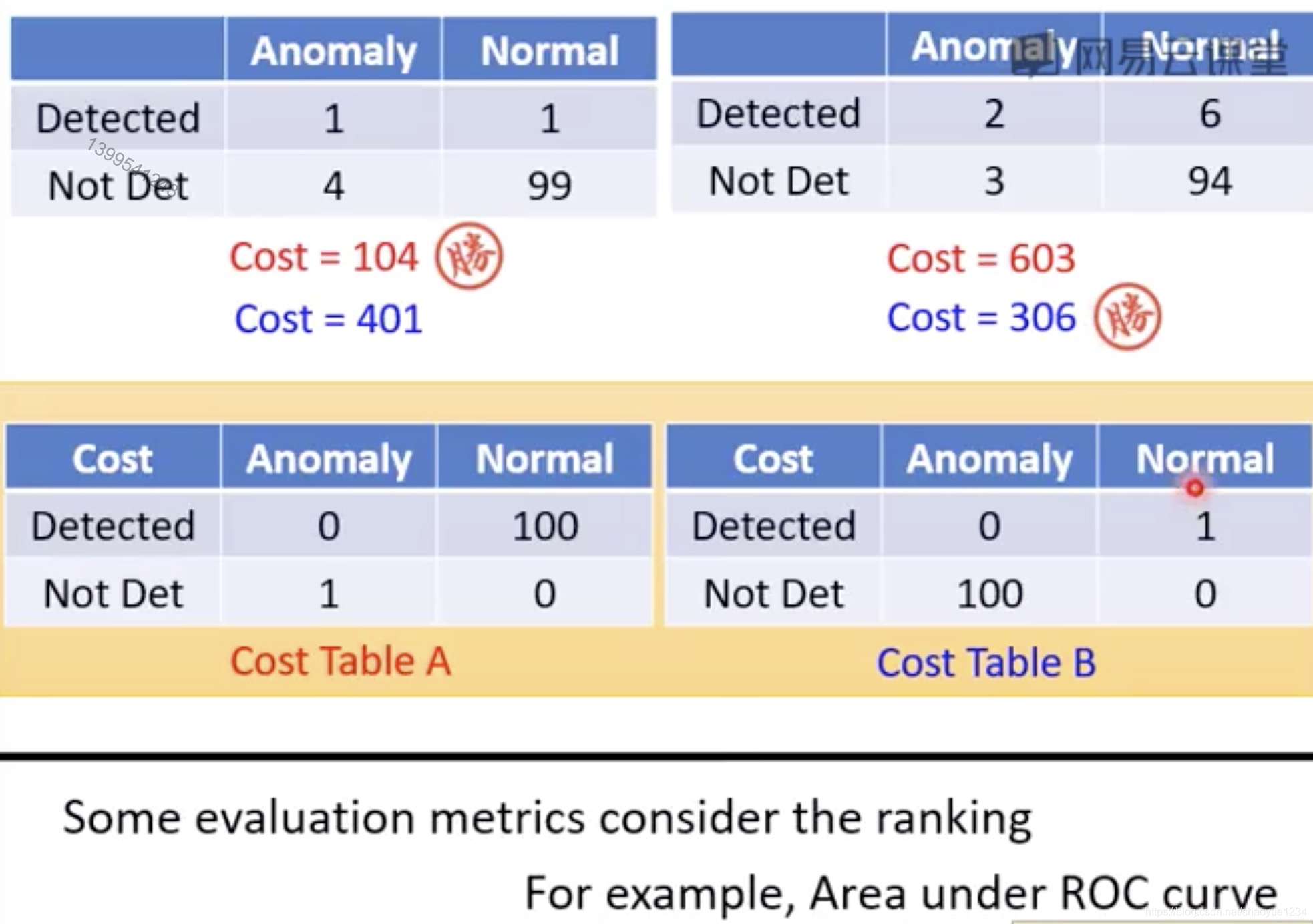
比如癌症检测,倾向于Cost tableB。 还有一些其它的衡量策略,如AUC。
直接用分类器可能会遇到的问题
比如一个猫狗分类器 会有比猫更像猫,比狗更像狗的

辛普森分类器,根据脸黄不黄判断

解决方法:学习一个异常confidence低的分类器,生成异常数据。

without labels
例子——twitch plays Pokemon
很多人在线玩这个游戏,因为有小白,有人故意的不好好玩,所以非常难玩。 假设:多数玩家都是正常的,检查出异常玩家
问题形式化
测试数据:{x1,x2,…xn} 找到一个函数,能判断输入x与训练数据是否相似。 说垃圾话(民主状态,通过vote决定),无政府状态(随机选)

问题:只有大量的x没有y
做法:
找到一个几率模型,判断是否是异常。超过阈值为真成功,低于阈值为异常。

假设每个发言都是二维的,用图表示概率:
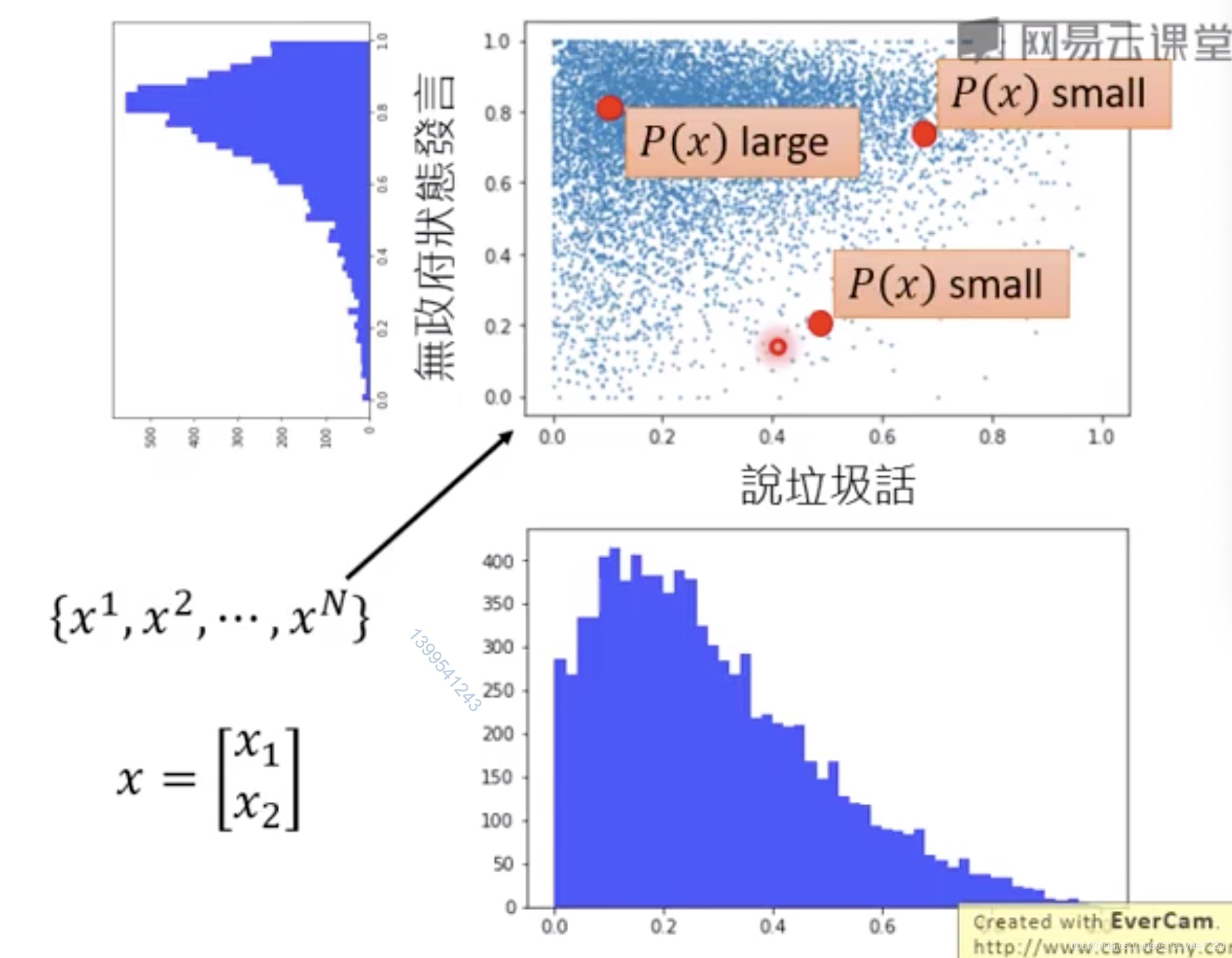
通过likelihood来决定
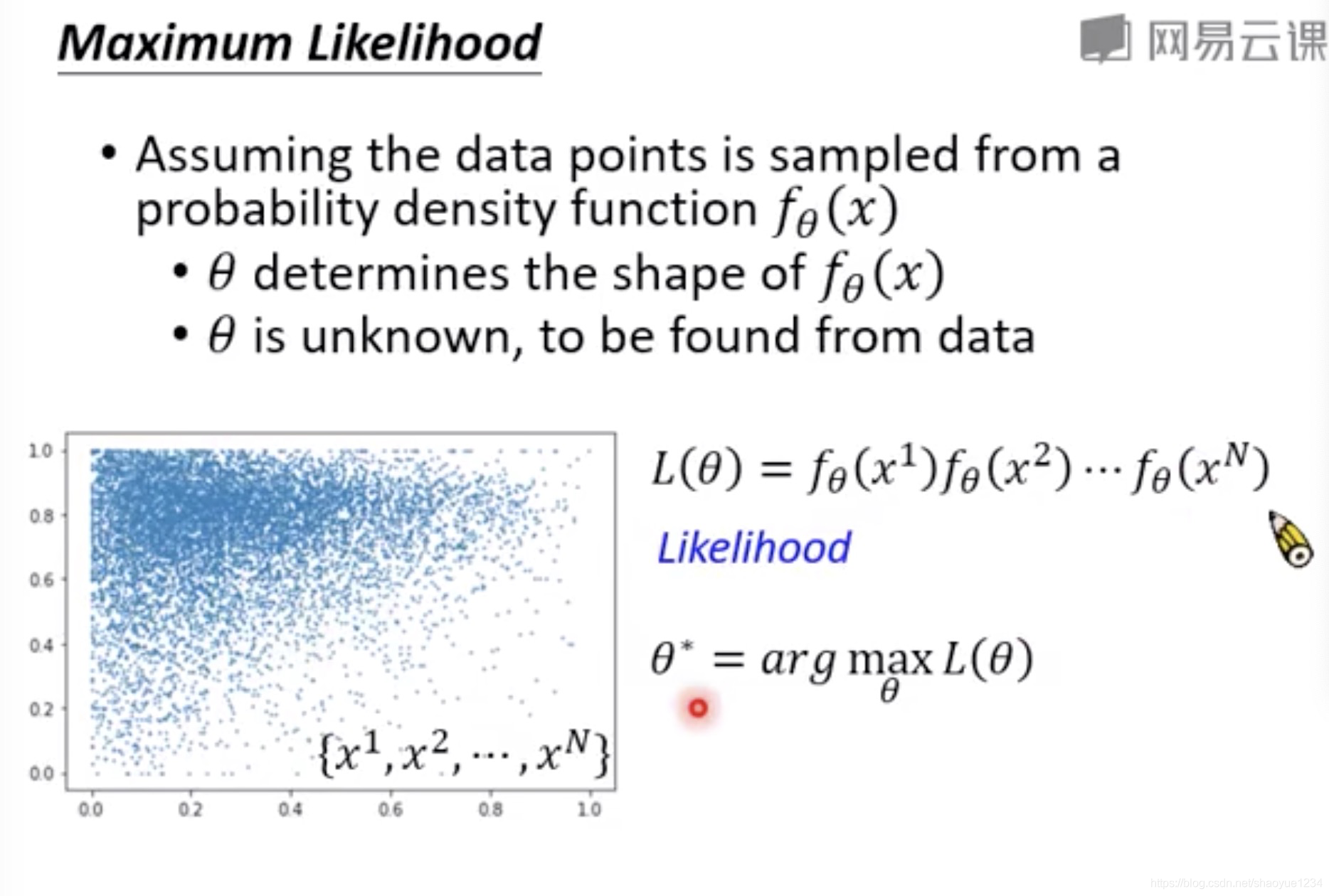
常用的概率密度模型为高斯模型

可能为其他模型,但是还没有涉及 高斯模型的最优解为
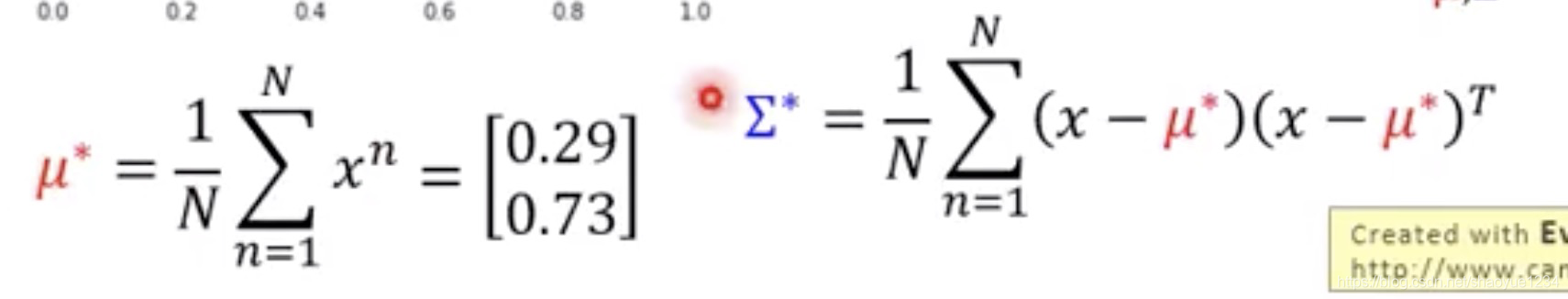
然后可以用这个模型来判断是否为异常,图中的等高线就是阈值
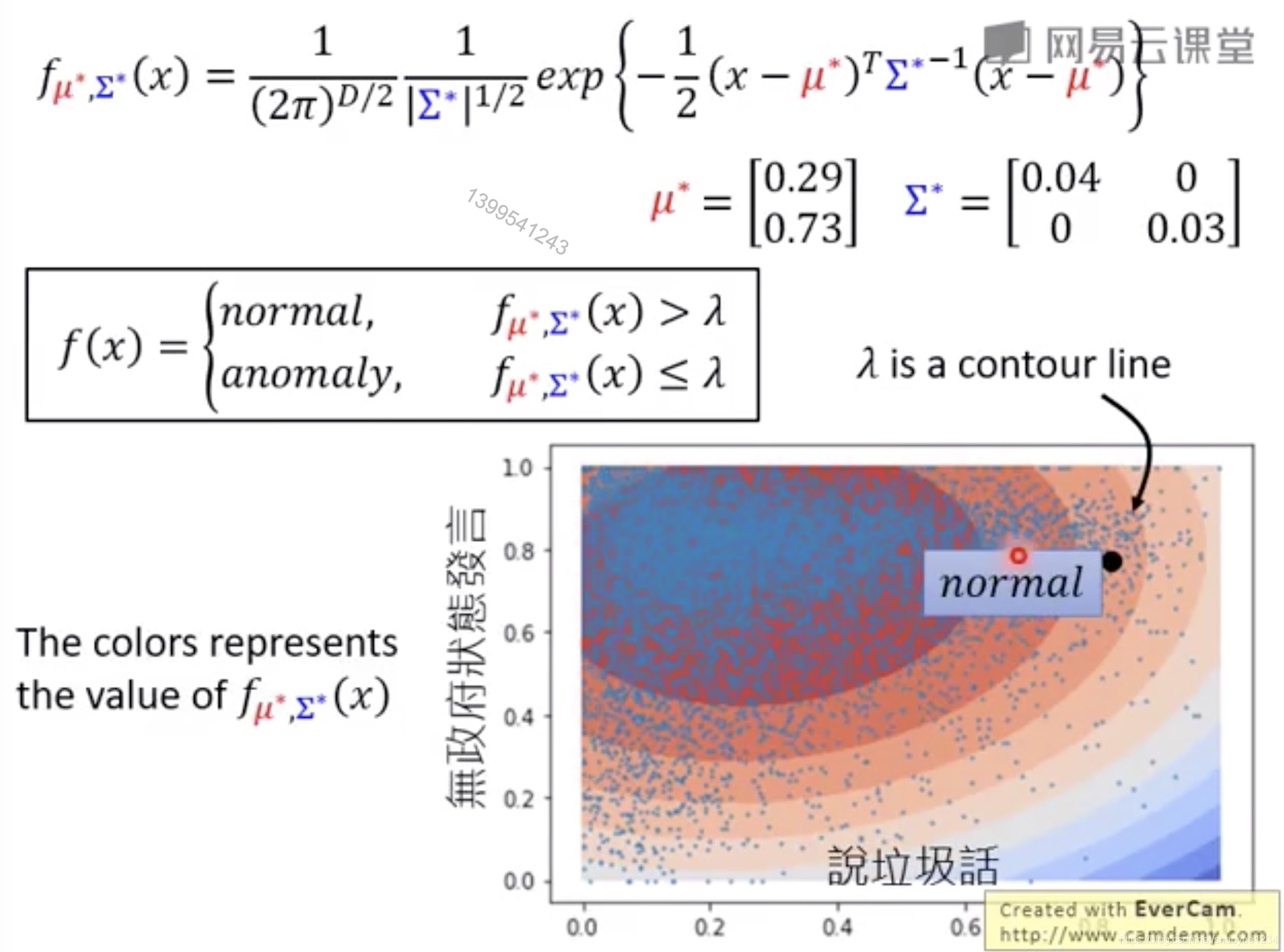
可以在更多feature上建模,不止是二维的图像。

其它方法
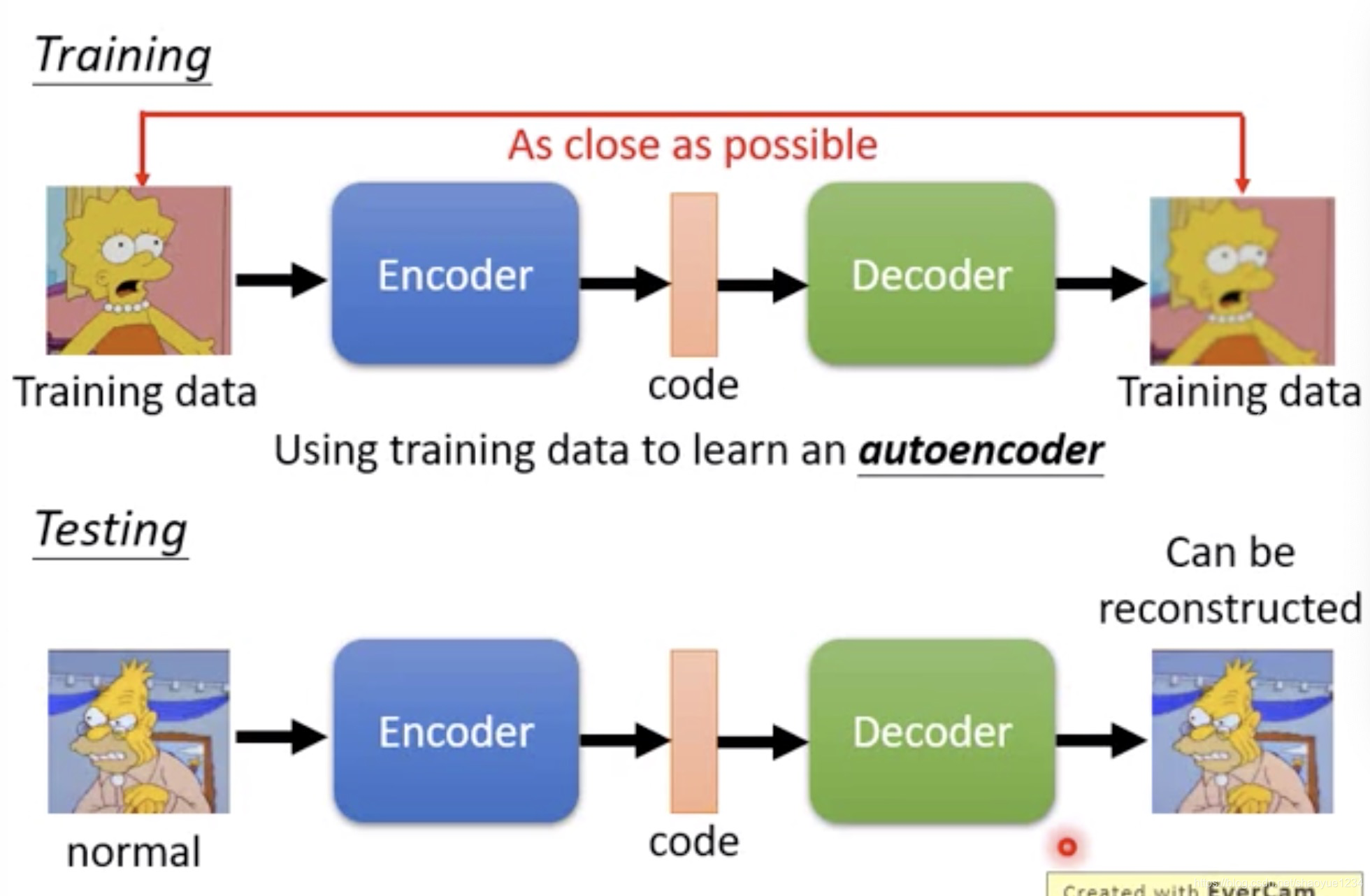
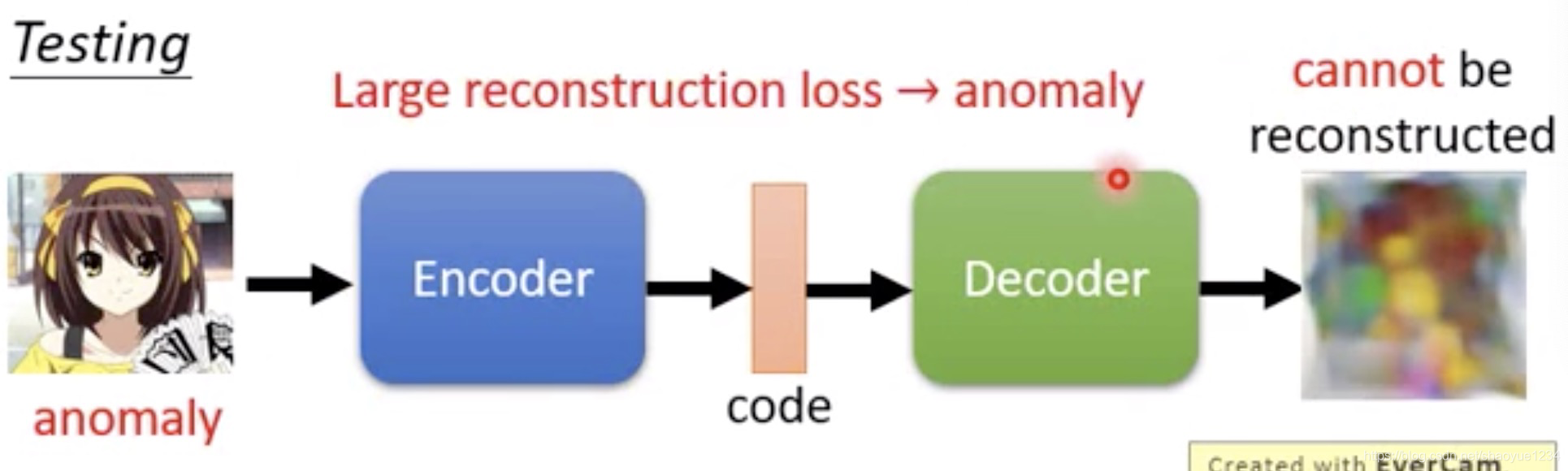
auto-encoder
正常还原度高,异常还原度低
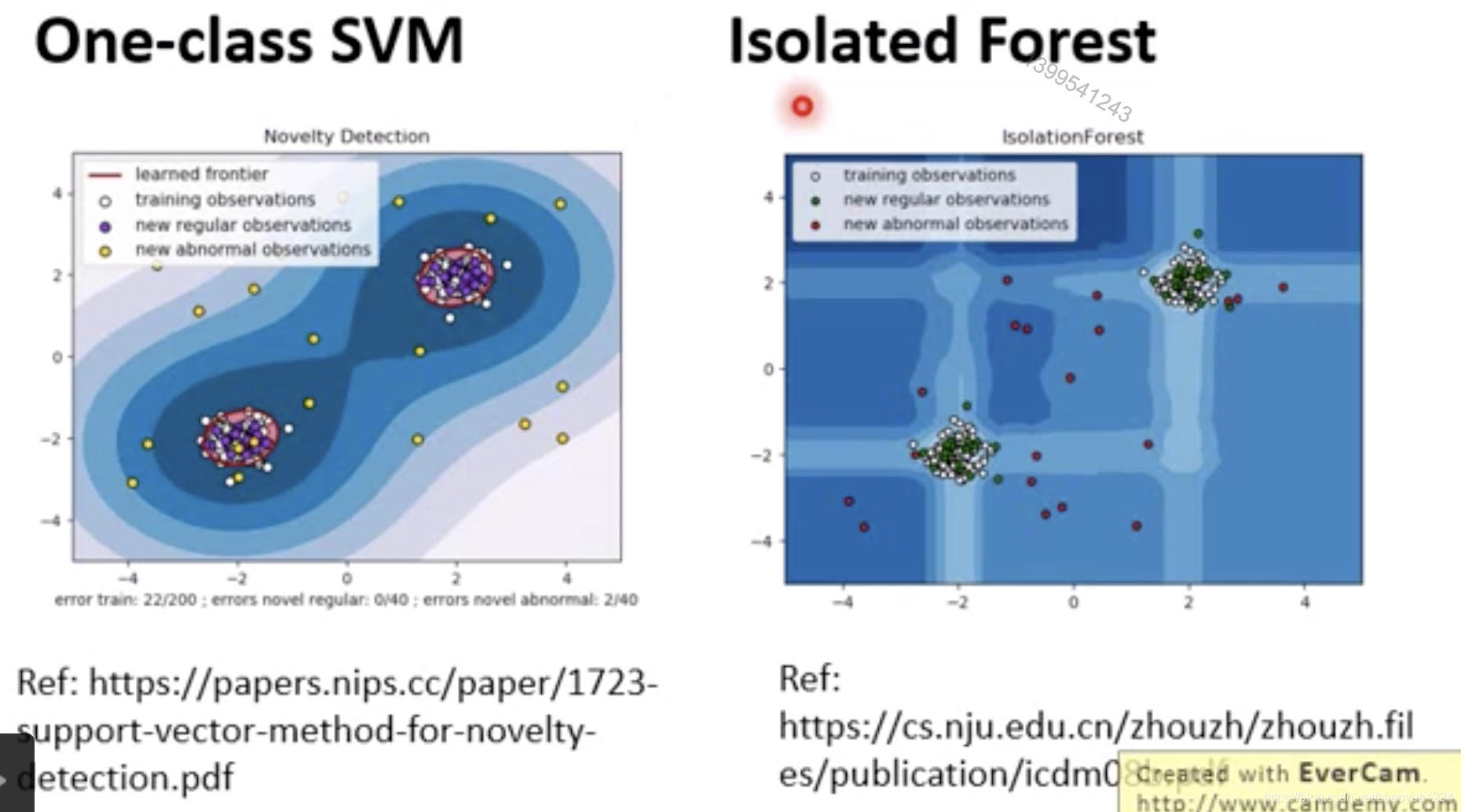
one-class SVM
isolated forest
总结
文档信息
- 本文作者:Echizen Mike
- 本文链接:https://echizenmike.github.io/2021/09/14/anomaly-detection/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)